発送データの事前処理が必要な理由 ダイレクトメールの発送データ、宛名リスト、データクレンジングが必要な理由とは
ダイレクトメールの発送データには様々な不備データが含まれているケースがあります。
不備データを事前に見つけ、発送前にデータをクレンジングするため、当社は全ての案件で発送データの事前処理を行っております。
なぜ、発送データの事前処理が必要なのか、その理由と効果をご紹介します。
データ処理が必要な理由
01
無駄な送料を削減するため
発送データは入力時のミスやデータ変換ミスなどの要因により不備データを含んでいるケースがあり
そのまま宛名出力してしまうと、配達できずに不着として戻って来てしまうことが懸念されます。
不備データが含まれる要因(一例)


- 登録時に入力ミスがあった
- CSV等の変換時にデータが誤って変換されてしまった
- WEB上のデータをコピーしての入力(住所が古い)、等
特にお客様情報を手入力する際に打ち間違いや読み間違いで入力ミスが起きるケースが多く、
時にはお客様ご自身が個人情報を入力される場合でも誤入力・誤変換が起きることがあります。
例えば10万件の発送データに1%の住所不備データが存在する場合、不備データを除外せずに発送してしまうと、郵送料だけでも下記のコストを無駄にすることになります。
はがきの場合(63円として計算)
100,000件×1%×63円= 63,000円
封書の場合(84円として計算)
100,000件×1%×84円= 84,000円
データ処理が必要な理由
02
重複によりお客様に不快な思いをさせないため
登録時の入力ミスでデータに「ゆらぎ」が生じてしまった場合、一人のお客様に複数のDMが届いてしまうケースがあります。
例えば、同一人物でも下記のような入力ゆらぎがあると、データ上は別人となってしまいます。
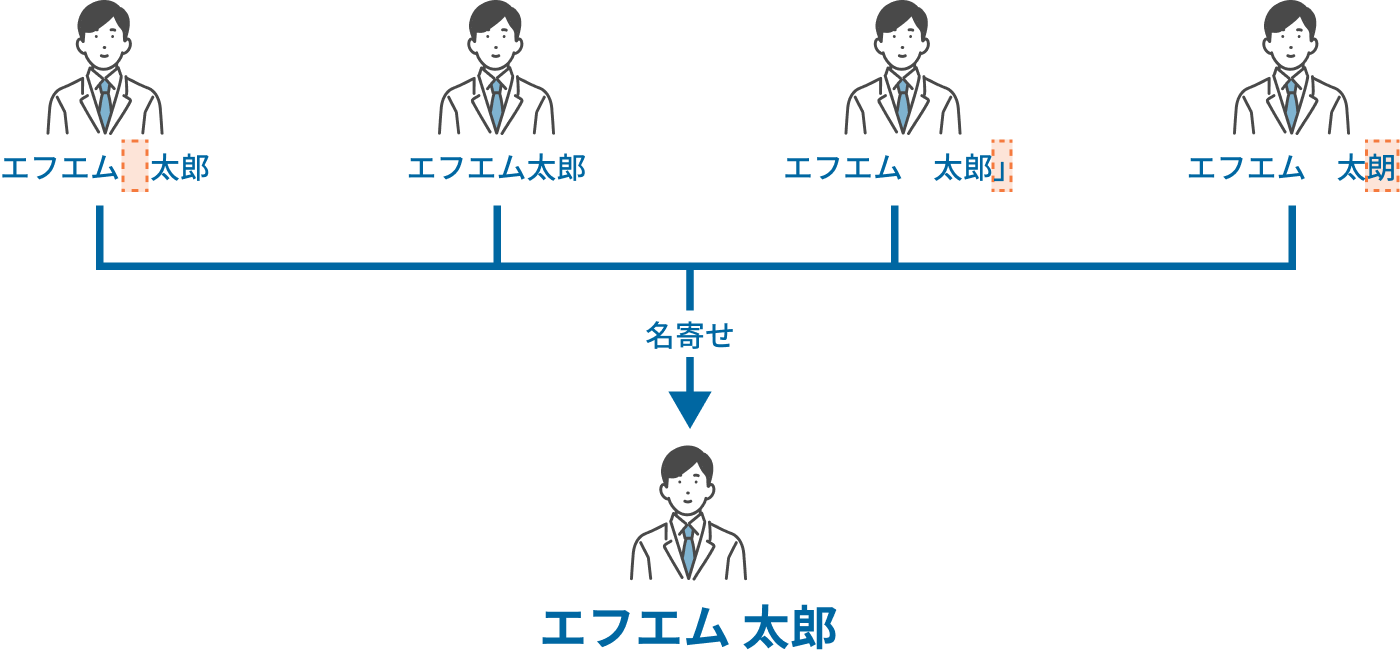
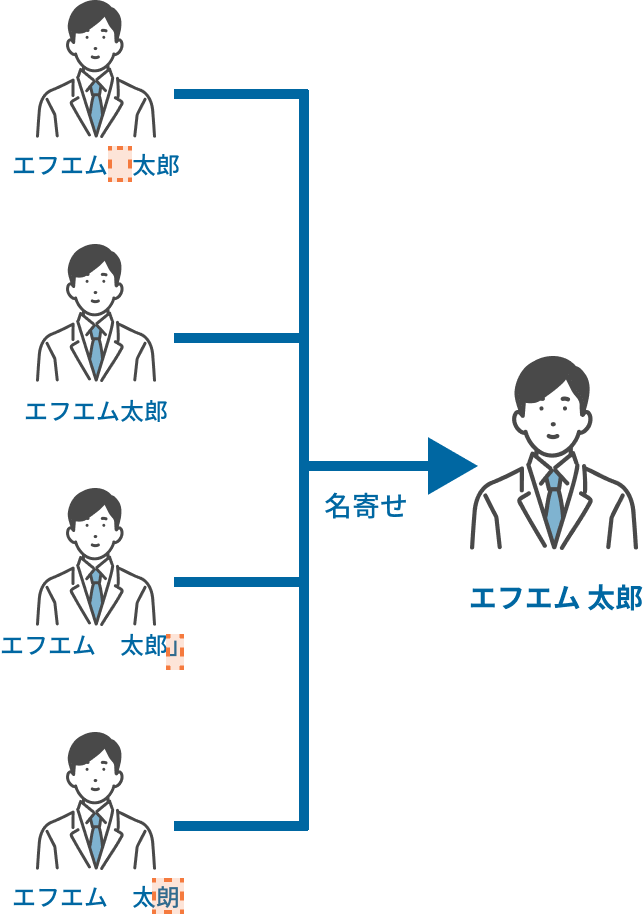
こういったデータは「名寄せ」という処理を行うことで見つけだすことができます。
事前に住所で名寄せをして発送対象データを特定することで、同一のお客様に複数のご案内を届けてしまい不快な思いをさせてしまうリスクを防ぐことができます。
また、重複した分の配送費は無駄になりますので、この処理を行うことで01の送料削減にもつながります。
データ処理が必要な理由
03
災害の発生による配達停止に対応
大規模な災害や大雪等の天候不順が発生すると、配達困難地域が発生することがあります。
また、現地の被害状況を考えると発送を見送るべき時もあります。こういった時には、郵便局や配送会社・自治体等が公表する情報をもとに被災地の郵便番号を確認し、
住所データとマッチングすることで対象地域のデータを除外することができます。
CHECK LIST
不備データを見つけるにはどういった処理が必要?
当社でのチェック内容をご紹介します。
![]()
ブランクチェック
発送に必要なデータや必須項目に抜けが無いかチェックします。
![]()
重複チェック
郵便番号・氏名を使用した重複チェックや、一戸一件の重複を行う方法として姓(項目として存在する場合や氏名の分割が可能な場合)・電話番号・番地以降情報等を使用してチェックします。
![]()
郵便番号チェック
桁数チェック、数値チェック、末尾00、9999999、 日本郵便のマスターを使用したチェック(住所情報で郵便番号が振れるか、元の郵便番号との整合性)します。
![]()
繰り返しチェック
氏名の繰り返しや住所の繰り返しが発生しているデータがないかチェックします。
![]()
文字列チェック
不要な記号等を含むデータのチェック。方書の確認「~方(宅)」も行います。
![]()
文字数チェック
納品データの桁数に収まるか、出力する帳票の印字スペースに収まるかをチェックします。
![]()
特定ワードチェック
お客様ご指定の文字列等がデータに含まれていないかチェックします。
![]()
外字チェック
JIS第1水準・第2水準の文字コード以外の文字がないかチェックします。




